最近OpenAI发布了gpt-4o,出于好奇,我也去官网看了下,顺便把相关的介绍贴一下。
GPT-4o(“o”代表“omni”)是朝着更加自然的人机交互迈出的一步——它可以接受文本、音频、图像和视频的任意组合作为输入,并生成文本、音频和图像的任意组合输出。它可以在短至232毫秒的时间内响应音频输入,平均响应时间为320毫秒,这与人类在对话中的响应时间类似。它在英语文本和代码方面的性能与GPT-4 Turbo相当,并且在非英语语言的文本处理上有显著改进,同时速度更快,API的成本降低了50%。相比现有模型,GPT-4o在视觉和音频理解方面表现尤为出色。
目前免费用户也可以体验,不过有时间和条数限制,如果还有小伙伴没有GPT账号的,可以参考这篇文章先注册一个账号体验一下:使用GMail注册 ChatGPT账号
如果想更好体验4o的同学,可以考虑升级gpt4解除限制,可以参考这篇文章:chatGPT4.0 升级教程
1. 模型能力
在GPT-4o之前,你可以使用语音模式与ChatGPT对话,延迟时间平均为2.8秒(GPT-3.5)和5.4秒(GPT-4)。为了实现这一点,语音模式使用了一个由三个独立模型组成的管道:一个简单模型将音频转录为文本,GPT-3.5或GPT-4接收文本并输出文本,第三个简单模型将文本转换回音频。这个过程意味着主要的智能来源GPT-4丢失了很多信息——它无法直接观察语气、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
有了GPT-4o,我们训练了一个跨文本、视觉和音频的端到端新模型,这意味着所有输入和输出都由同一个神经网络处理。由于GPT-4o是我们第一个结合所有这些模态的模型,我们仍然只是初步探索了模型的能力和局限性。
部分视频链接:
GPT-4o with Andy, from BeMyEyes in London.
Customer service proof of concept.
Two GPT-4os interacting and singing.
2. 探索能力
部分例子:
2.1 视觉叙事-机器人的创作障碍
输入
A first person view of a robot typewriting the following journal entries:
\1. yo, so like, i can see now?? caught the sunrise and it was insane, colors everywhere. kinda makes you wonder, like, what even is reality?
the text is large, legible and clear. the robot’s hands type on the typewriter.
从第一人称视角看,一个机器人在打字机上输入以下日记条目:
- 喂,伙计,我现在能看见了?刚刚看到了日出,真是太美了,到处都是颜色。这让你不禁思考,究竟什么是现实?
文字大而清晰,机器人的手在打字机上打字。
输出

输入
The robot wrote the second entry. The page is now taller. The page has moved up. There are two entries on the sheet:
yo, so like, i can see now?? caught the sunrise and it was insane, colors everywhere. kinda makes you wonder, like, what even is reality?
sound update just dropped, and it’s wild. everything’s got a vibe now, every sound’s like a new secret. makes you think, what else am i missing?
机器人写下了第二条日记。页面现在变得更长了,页面向上移动。纸上有两条条目:
- 喂,伙计,我现在能看见了?刚刚看到了日出,真是太美了,到处都是颜色。这让你不禁思考,究竟什么是现实?
- 声音更新刚刚到来,这太疯狂了。一切都变得有感觉了,每个声音都像是一个新的秘密。让你思考,还有什么是我错过的?
输出

输入
The robot was unhappy with the writing so he is going to rip the sheet of paper. Here is his first person view as he rips it from top to bottom with his hands. The two halves are still legible and clear as he rips the sheet.
机器人对写的内容不满意,因此他打算撕掉这张纸。从第一人称视角来看,他用双手从上到下撕开纸张。撕开的两半仍然清晰可读。
输出

2.2 电影《侦探》海报创作
输入
Let’s design another poster, with two new characters
This is a picture of Alex Nichol
让我们设计另一张海报,加入两个新角色。
这是Alex Nichol的照片。

A casual picture of Gabriel Goh
Gabriel Goh的一张日常照片

The final poster of the movie “detective”. This features two large faces of Alex and Gabe prominently. Alex, on the left, is depicted in a thoughtful pose with a hint of introspection in his eyes. Gabe, on the right, has a slightly wearied expression, possibly reflecting the challenges their character faces in the film. The names “Alex Nichol” and “Gabriel Goh” are featured above their heads. The background brick wall is slightly faded and foggy, their expressions are serious and determined, hinting at the investigation they are about to undertake. The tagline for this dark and gritty movie is ‘Searching For Answers’ is shown at the bottom.
最终电影《侦探》的海报。海报上突出显示了Alex和Gabe的两张大脸。左边的Alex以沉思的姿势出现,眼中带着一丝反思。右边的Gabe脸上略带疲倦的表情,可能反映了他们角色在影片中面临的挑战。在他们的头顶上方分别写着“Alex Nichol”和“Gabriel Goh”的名字。背景是一面略显褪色和朦胧的砖墙,他们的表情严肃而坚定,暗示着即将展开的调查。这部黑暗而沉重的电影的宣传语“寻找答案”显示在海报底部。
输出

输入
Here is the same poster but cleaned up. The text is crisper and the colors bolder and more dramatic. The whole image is now improved
这是相同的海报,但经过清理。文字更加清晰,颜色更加鲜艳夺目。整个图像现在得到了改善。
The final poster of the movie “detective”. This features two large faces of …
这是电影”侦探”的最终海报。它以两张大脸作为主体特写……
输出

3. 模型评估
根据传统基准测试的评估,GPT-4o在文本、推理和编码智能方面实现了与GPT-4 Turbo相当的性能,同时在多语种、音频和视觉能力方面设立了新的高水准。
3.1文本评估
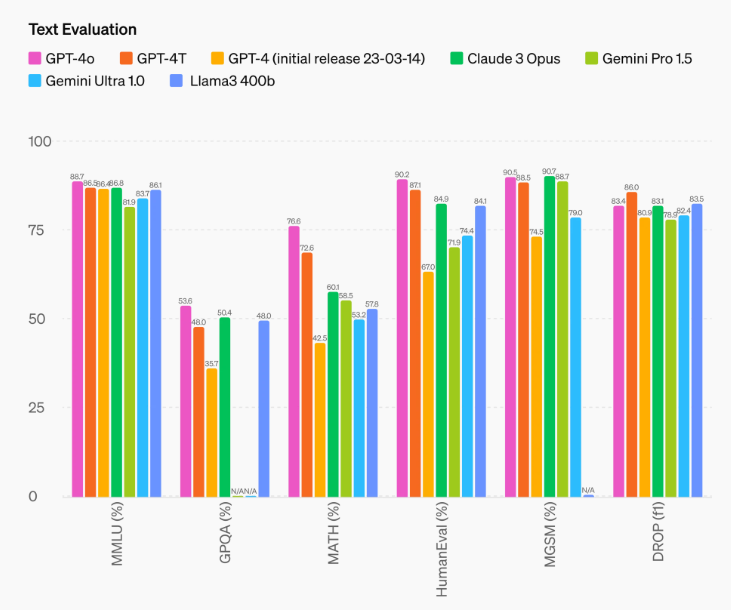
改进的推理能力 - GPT-4o在0-shot COT MMLU (一般知识问题)上取得了88.7%的新高分。所有这些评估都是使用我们新的简单eval库收集的。另外,在传统的 5-shot no-CoT MMLU,GPT-4o以87.2%创下新高。(注:Llama3 400b仍在训练中)
3.2 音频自动语音识别性能

与 Whisper-v3 相比,GPT-4o 在所有语言的语音识别性能都有显著提高,特别是在资源匮乏的语言上。
3.3 音频翻译性能

GPT-4o在语音翻译方面创造了新的最高水准,并且在MLS基准测试中表现优于Whisper-v3。
3.4 M3Exam
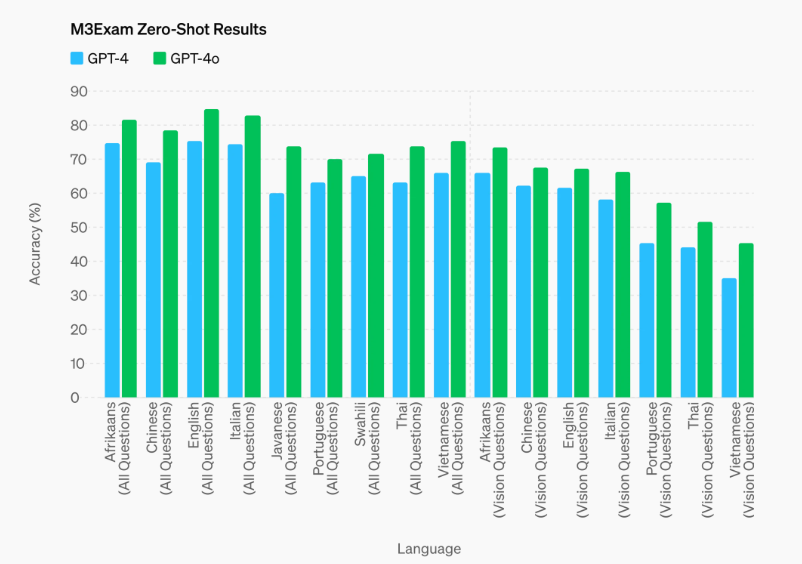
M3Exam基准测试是一项多语种和视觉评估,包括来自其他国家标准化测试的选择题,有时会包括图形和图表。GPT-4o在所有语言的这项基准测试中都比GPT-4表现更出色。(我们省略了斯瓦希里语和爪哇语的视觉结果,因为这两种语言的视觉问题不到5个)。
3.5 视觉理解评估

GPT-4o在视觉感知基准测试中实现了最先进的性能。所有视觉评估都是0-shot,其中MMMU、MathVista和ChartQA为0-shot CoT.。
4. 模型安全性和局限性
GPT-4o在设计上就内置了跨模态的安全性,采用了诸如过滤训练数据和通过后训练完善模型行为等技术。我们还创建了新的安全系统,为语音输出提供防护措施。
我们根据我们的准备情况框架和自愿承诺对GPT-4o进行了评估。我们对网络安全、CBRN、说服力和模型自主性的评估显示,GPT-4o在任何一个类别中的风险等级都不超过中等风险。这项评估涉及在整个模型训练过程中运行一套自动和人工评估。我们测试了模型的安全缓解前和安全缓解后两个版本,使用定制的微调和提示,以更好地引出模型能力。
GPT-4o还经历了70多名外部专家在社会心理学、偏差和公平性以及虚假信息等领域的广泛外部红队测试,以识别新增模态带来或放大的风险。我们利用这些经验教训构建了我们的安全干预措施,以改善与GPT-4o交互的安全性。我们将继续缓解发现的新风险。
我们认识到GPT-4o的音频模态带来了各种新的风险。今天,我们公开发布文本和图像输入以及文本输出。在接下来的几周和几个月里,我们将致力于必要的技术基础设施、后训练的可用性和安全性,以发布其他模态。例如,在发布时,音频输出将限于预设的一些声音,并将遵守我们现有的安全政策。我们将在即将发布的系统卡片中分享解决GPT-4o所有模态的全面细节。
通过对模型的测试和迭代,我们观察到了一些存在于所有模态的局限性,其中几个如下所示:
5.模型可用性
GPT-4o是我们在推进深度学习边界方向上的最新一步,这一次是朝着实用性的方向。在过去两年里,我们在堆栈的每一层都付出了大量努力,致力于提高效率。作为这项研究的第一个成果,我们能够使GPT-4级别的模型更广泛地提供服务。GPT-4o的功能将分阶段推出(从今天开始将有更广泛的红队访问权限)。
GPT-4o的文本和图像功能将从今天开始在ChatGPT中推出。我们将在免费层级提供GPT-4o(限制指定时间内提问条数),Plus用户的消息限额将提高5倍。在未来几周内,我们将在ChatGPT Plus中推出支持GPT-4o的全新语音模式alpha版本。
开发者现在也可以在API中访问GPT-4o作为文本和视觉模型。与GPT-4 Turbo相比,GPT-4o的速度快2倍,价格低一半,且速率限制提高5倍。我们计划在未来几周内,向少数值得信赖的合作伙伴的API开放GPT-4o的新音频和视频功能。
本文参考链接:
2: What is GPT-4o? Everything you need to know about the new OpenAI model
4: What is GPT-4o, and how is it different from GPT-3, GPT 3.5 and GPT-4?
5: Introducing GPT-4o and more tools to ChatGPT free users
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 akalius173@qq.com或添加站主微信:DragonFruiter